















This article (and the next) focuses on trends in the market—an explanation as to why markets trend, reasons why it is good to know that markets trend, then finally, a large research section into how much markets trend. This analysis will initially be shown on 109 market indices that involve domestic, international, and commodity sectors. Following that the full list of all S&P GICS sectors, industry groups, and industries are shown following the same format. There is a great amount of data in these two sections. I try to slice through it with simple analysis, keeping in mind that lots of data does not equate to information.
Why Markets Trend
Trends in markets are generally caused by short-term supply-and-demand imbalances with a heavy overdose of human emotion. When you buy a stock, you know that someone had to sell it to you. If the market has been rising recently, then you know you will probably pay a higher price for it, and the seller also knows he can get a higher price for it. The buying enthusiasm is much greater than the selling enthusiasm.
I hate it when the financial media makes a comment when the market is down by saying that there are more sellers than buyers. They clearly do not understand how these markets work. Based on shares, there are always the same number of buyers and sellers; it is the buying and selling enthusiasm that changes.
Trending is a positive feedback process. Even Isaac Newton believed in trends with his first law of motion, which stated that an object at rest stays at rest, while an object in motion stays in motion, with the same speed and in the same direction unless acted on by an unbalanced force. Hey, an apple will continue to fall until it hits the ground. Positive feedback is the direct result of an investor’s confidence in the price trend. When prices rise, investors confidently buy into higher and higher prices.
Supply and Demand
A buyer of a stock, which is the demand, bids for a certain amount of stock at a certain price. A seller, which is the supply, offers a certain amount at a certain price. I think it is fair to say that one buys a stock with the anticipation that they can sell it later to someone at a higher price. Not an unreasonable desire, and probably what drives most investors. The buyer has no idea who will sell it to him, or why they would sell it to him. He may assume that he and the seller have a complete disagreement on the future value of that stock. And that might be correct; however, the buyer will never know. In fact, the buyer just might be the seller’s person who buys it from him at a higher price.
The reasons for buying and selling stock are complex and impossible to quantify. However, when they eventually agree, what is it that they agreed on? Was it the earnings of the company? Was it the products the company produces? Was it the management team? Was it the amount of the stock’s dividend? Was it the sales revenues? As it turns out, it was none of those things; the transaction was settled because they agreed on the price of the stock, and that alone determines profit or loss. Changes in supply and demand are reflected immediately in price, which is an instantaneous assessment of supply and demand.
What Do You Know about This Chart?
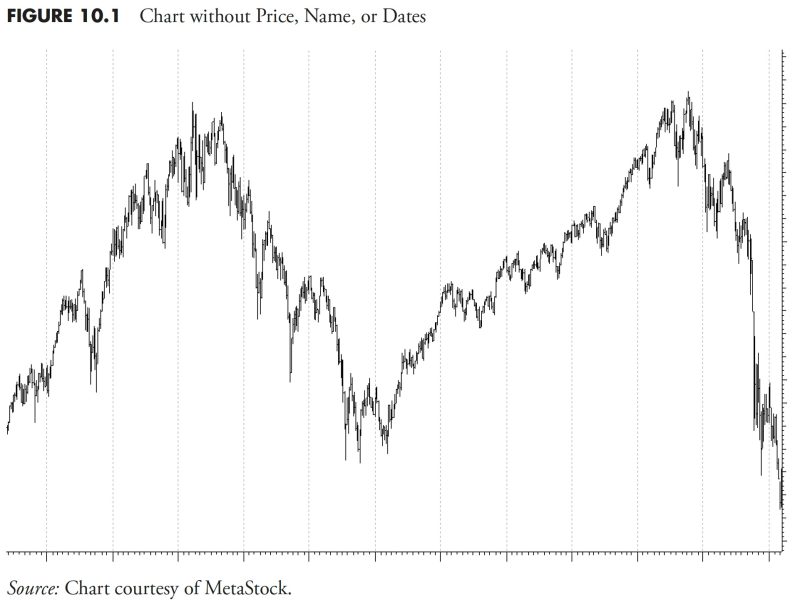
In Figure 10.1, I have removed the price scale, the dates, and the name of this issue; now let me ask you some questions about this issue.
Is this a chart of daily prices, weekly prices, or 30-minute prices?
Is this a chart of a stock, a commodity, or a market index? (Okay, I’ll give you this much, it is a daily price chart of a stock over a period of about six years.)
During this period of time, there were 11 earnings announcements. Can you show me where one of those announcements occurred and, if you could, whether the earnings report was considered good or bad?
Also during the period of time for this chart, there were seven Federal Open Market Committee (FOMC) announcements. Can you tell me where one of them occurred, and whether the announcement was considered good or bad?
Does this stock pay a dividend?
Hurricane Katrina occurred during this period displayed on this chart; can you tell me where it is?
Finally, would you want to buy this stock at the beginning of the period displayed and then sell it at the end of the period (right side of chart)?
I doubt, in fact, I know you cannot answer most of the above questions with any tool other than guessing. The point of this exercise is to point out that there is always and ever noise in stock prices. This noise comes in hundreds of different colors, sizes, shapes, and media formats. The bottom line is that it is just noise. The financial media bombards us all day long with noise. I do not think they do it maliciously; they do it because they believe they are giving you valuable information to help you make investment decisions. Nothing could be further from the truth.
Of course, question number 7 is the one question that most can answer, because from the chart a buy-and-hold investment during the data displayed clearly resulted in no investment growth.
However, let me tell you what I see as shown in Figure 10.2. I see two really good uptrends and, if I had a trend-following methodology that could capture 65 percent to 75 percent of those uptrends, I would be happy. I also see two good downtrends, and if I had a methodology that could avoid about 75 percent of them, I would also be happy. If you could do that for the amount of time shown on the chart below, then you would come out considerably better off than the buy-and-hold investor. I generally only participate in the long side of the market and move to cash or cash equivalents when defensive. However, a long-short strategy could possibly derive even greater profit.
Trend vs. Mean Reversion
I prefer to use a market analysis methodology called trend following. Sometimes it should be called trend continuation. Why? Trend analysis works on the thoroughly researched concept that once a trend is identified, it has a reasonable probability to continue. I know that is the case because, most of the time, markets are trending markets, and I see no reason to adopt a different strategy during a period of mean reverting, such as is experienced in the market from time to time.
You can think of trend following as a positive feedback mechanism. Mean reverting measures are those that oscillate between predetermined parameters; oftentimes the selection of those parameters is the problem. Mean reversion strategies are clearly superior during those volatile sideways times, but the implementation of a mean reverting process requires a level of guessing that I refuse to be a part of. You can think of mean reversion as a negative feedback mechanism.
In technical analysis, there are many mean reverting measures that could be used. They are the ones where you frequently hear the terms overbought and oversold. Overbought means the measurement shows that prices have moved upward to a limit that is predefined. Oversold means the opposite—prices have moved down to a predetermined level. The problem with that type of indicator or measurement is that a parameter needs to be set beforehand to know what the overbought and oversold levels are. Also, if you believe something mean reverts, you will probably have difficulty in determining the rate of reversion. For mean reversion to be relevant, there must be a meaning tied to average (mean) and, since most market data does not adhere to normal distributions, the mean isn’t as meaningful (sic). Kind of like charting net worth and removing billionaires to make the data less skewed and therefore a more meaningful average.
Clearly, mean reverting measurements would work better in highly volatile markets, such as we witness from time to time. One might ask the question: Why don’t you incorporate both into your model? A fair question, but one that shows the inquiry is forgetting that hindsight is not an analysis tool that will serve you well. When do you switch from one strategy (trend following) to the other (mean reversion)? Therein lies the problem.
Another question that might be asked is why not use adaptive measures to help identify the two types of markets. Again, another fair question! I think the lag between the two types of markets and the fact that often there is no clear period of delineation is the issue. It is a natural instinct to want to change the strategy in order to respond more quickly from one to the other. Natural instincts are what we are trying to avoid, simply because they are generally wrong, and painfully wrong at the worst times.
The transition from trend following to mean reversion can be difficult to see except with 20/20 hindsight. For example, when you view a chart which clearly has gone from trending to reversion, from that point, if we had used a simple mean reverting measurement, we would have looked like geniuses. However, in reality, periods like that have existed many times in the past in overall trending markets. Then the next problem becomes when to move away from a mean reverting strategy back to a trend following one. Again, hindsight always gives the precise answer, but in reality it is extremely difficult to implement in real time.
The bottom line is that with markets that generally trend most of the time, keeping a set of rules and stop loss levels in place will probably always win over the long-term. Sharpshooting the process is the beginning of the end. Trend following is somewhat similar to a momentum strategy except for two significant differences: one, momentum strategies generally rank past performance for selection, and two, often they do not utilize stop-loss methods, instead moving in and out of top performers. They both rely on the persistence of price behavior.
Trend Analysis
If one is going to be a trend follower, what is the first thing that must be done (rhetorical)? In order to be a trend follower, you must first determine the minimum length trend you want to identify. You cannot follow every little up and down move in the market; you must decide what the minimum trend length is that you want to follow. Once this is done, you can then develop trend-following indicators using parameters that will help identify trends in the market based on the minimum length you have decided on.
Figure 10.3 is an example of various trend-following periods. The top plot is the Nasdaq Composite index. The second plot is a filtered wave showing the trend analysis for a fairly short-term-oriented trend system. This is for traders and those who want to try to capture every small up and down in the market; a process that is not adopted by this author. The third plot is the ideal trend system, where it is obvious that you buy at the long-term bottom and sell at the long-term top. You must realize that this trend analysis can only be done with perfect 20/20 hindsight, and is probably even more difficult than the short-term process shown in the second plot. The bottom plot is a trend analysis process that is at the heart of the concepts discussed in this book. It is a trend-following process that realizes you cannot participate in every small up and down move, but try to capture most of the up moves and avoid most of the down moves.
There is a concept developed by the late Arthur Merrill called Filtered Waves. A filtered wave is the measurement of price movements in which only the movement that exceeds a predetermined percentage is counted. The price component used in this concept needs to be decided on as to whether to use just the closing prices for the filtered wave or use a combination of high and low prices. This would mean that, while prices are rising, the high would be used, and while prices are falling, the low price would be used. I personally prefer the high and low prices, as they truly reflect the price movements, whereas the closing prices only would eliminate some of the data.
For example, in Figure 10.4 , the background plot is the S&P 500 Index with both the close C and the high low H-L filtered waves overlaid on the prices. You can see that the H-L filtered wave techniques picks up more of the data; in fact, it shows a move of 5 percent in the middle of the plot that the Close only version did not show. In this particular example, the zigzag line uses a filter of 5 percent, which means that each time it changes direction, it had previously moved at least 5 percent in the opposite direction. There is one exception to this, and that is the last move of the zigzag line (there is a similar discussion in an earlier chapter). It merely moves to the most recent close regardless of the percentage moved so it must be ignored.
The bottom plot in Figure 10.5 shows the filtered wave by breaking down the up moves and down moves and then counting the number of periods that were in each move. There are three horizontal lines on that plot; the middle one is at zero, which is where the filtered wave changes direction. In this example, the top and bottom lines are at +21 and -21 periods, which mean that anytime the filtered wave exceeds those lines above or below, the trend has lasted at least 21 periods. Notice that, in this example, there was a period at the beginning (highlighted) where the market moved up and down in 5% or greater moves with high frequency, but never lasted long enough to exceed the 21 boundaries. Then, in the second half of the chart, there were two good moves that did exceed the 21 boundaries. This is a good example of a chart where there was a trendless market (first half) and a trending market (second half). I used the high-low filtered wave of 5 percent and 21 days for the minimum length because that is what I prefer to use for most trend analysis.
The following research was conducted using the high-low filtered wave using various percentages and various trend length measures. The research was conducted on a wide variety of market prices, such as most domestic indices, most foreign indices, all of the S&P sectors and industry groups; 109 issues in all. I offer commentary throughout so you can see that this was a robust process. Any indices or price series that is missing was probably because of an inadequate amount of data, as you need a few years of data to determine a series’ trendiness. The goal of this research was to determine that markets generally trend and if there are some markets that trend better than others. Following this large section, the trend analysis will be shown using the S&P GICS data on sectors, industry groups, and industries.
Table 10.1 is the complete list of indices used in this study along with the beginning date of the data.
I did multiple sets of data runs, but will explain the process by showing just one of them. Table 10.2 is the data run through all 109 indices for the 5% filtered wave and 21 days for the trend to be identified. The first column is the name of the index (they are in alphabetical order), while the next four columns are the results of the data runs for the total trend percentage, the uptrend percentage, the downtrend percentage, and the ratio of uptrends to downtrends.
The total reflects the amount of time relative to the amount of all data available that the index was in a trend mode defined by the filtered wave and trend time; in the case below, a trend had to last at least 21 days and a move of 5% or greater. The up measure is just the percentage of the uptrend relative to the amount of data. Similarly, the downtrend is the percentage of the downtrend to the amount of data. If you add the uptrend and downtrend, you will get the total trend.
The last column is the U/D Ratio, which is merely the uptrend percentage divided by the downtrend percentage. If you look at the first entry in Table 10.2, the AMEX Composite trends 71.18 percent of the time, with 56.16% of the time in an uptrend and 15.03% of the time in a downtrend. The U/D Ratio is 3.74, which means the AMEX Composite trends up almost 4 (3.74) times more than it trends down. You can verify the amount of data in the Indices Date table shown early to see if it was adequate enough for trend analysis. It is not shown, but the complement of the total would give you the amount of time the index was trendless.
At the bottom of each table is a grouping of statistical measures for the various columns. Here are the definitions of those statistics:
Mean. In statistics, this is the arithmetic average of the selected cells. In Excel, this is the Average function (go figure). It is a good measure as long as there are no large outliers in the data being analyzed.
Average deviation. This is a function that returns the average of the absolute deviations of data points from their mean. It can be thought of as a measure of the variability of the data.
Median. This function measures central tendency, which is the location of the center of a group of numbers in a statistical distribution. It is the middle number of a group of numbers; that is, half the numbers have values that are greater than the median, and half the numbers have values that are less than the median. For example, the median of 2, 3, 3, 5, 7, and 10 is 4. If there are a wide range of values that are outliers, then median is a better measure than mean or average.
Minimum. Shows the value of the minimum value of the cells that are selected.
Maximum. Shows the value of the maximum value of the cells that are selected.
Sigma. Also known as standard deviation. It is a measure of how widely values are dispersed from their mean (average).
Geometric mean. First of all, it is only good for positive numbers and can be used to measure growth rates, etc. It will always be a smaller number than the mean.
Harmonic mean. Simply the reciprocal of the arithmetic mean, or could be stated as the arithmetic mean of the reciprocals. It is a value that is always less than the geometric mean, and like the geometric mean, can only be calculated on positive numbers and generally used for rates and ratios.
Kurtosis. This function characterizes the relative peakedness or flatness of a distribution compared with the normal distribution (bell curve). If the distribution is “tall”, then it reflects positive kurtosis, while a relatively flat or short distribution (relative to normal) reflects a negative kurtosis.
Skewness. This characterizes the degree of symmetry of a distribution about its mean. Positive skewness reflects a distribution that has long tails of positive values, while negative skewness reflects a distribution with an asymmetric tail extending toward more negative values.
Trimmed mean (20 percent). This is a great function. It is the same as the Mean, but you can select any number or percentage of numbers (sample size) to be eliminated at the extremes. A great way to eliminate the outliers in a data set.
Trendiness Determination Method One
This methodology for trend determination looks at the average of multiple sets of raw data. An example of just one set of the data was shown previously in Table 10.2, which looks at a filtered wave of 5% and a minimum trend length of 21 days. Following Table 10.3 is an explanation of the column headers for Trendiness One in the analysis tables that follow.
Trendiness average. This is the simple average of all the total trending expressed as a percentage. The components that make up this average are the total trendiness of all the raw data tables, in which the total average is the average of the uptrends and downtrends as a percentage of the total data in the series.
Rank. This is just a numerical ranking of the trendiness average, with the largest total average equal to a rank of 1.
Avg. U/D. This is the average of all the raw data tables’ ratio of uptrends to downtrends. Note: If the value of the Avg. U/D is equal to 1, it means that the uptrends and downtrends were equal. If it is less than 1, then there were more downtrends.
Uptrendiness WtdAvg. This is the product of column Trendiness Average and column Avg. U/D. Here the Total Trendiness (sum of up and down) is multiplied by their ratio, which gives a weighted portion to the upside when the ratio is high. If the average of the total trendiness is high and the uptrendiness is considerably larger than the downtrendiness, then this value (WtdAvg) will be high.
Rank. This is a numerical ranking of the Up Trendiness WtdAvg, with the largest value equal to a rank of 1.
Table 10.4 shows the complete results using Trendiness One methodology.
Trendiness Determination Method Two
The second method of trend determination uses the raw data averages. For example, the up value is calculated by using the raw data up average compared to the raw data total average, which therefore means it only is using the amount of data that is trending and not the full data set of the series. This way, the results are dealing only with the trending portion of the index, and if you think about it, when the minimum trend length is high and the filtered wave is low, there might not be that much trending. Table 10.5 shows the column headers followed by their definitions.
Up. This is the average of the raw data Up Trends as a percentage of the Total Trends.
Down. This is the average of the raw data Down Trends as a percentage of the Total Trends.
Up rank. This is the numerical ranking of the Up column, with the largest value equal to a rank of 1.
Table 10.6 shows the results using Trendiness Two methodology.
Comparison of the Two Trendiness Methods
Figure 10.6 compares the rankings using both “Trendiness” methods. Keep in mind we are only using uptrends, downtrends, and a derivative of them, which is up over down ratio. The plot below is informally called a scatter plot and deals with the relationships between two sets of paired data.
The equation of the regression line is from high school geometry and follows the expression: y = mx + b, where m is the slope and b is the y-intercept (where it crosses the y axis); x is known as the independent variable or the predictor variable and y is the dependent variable or response variable. The expression that defines the regression (linear least squares) shows that the slope of the line (m) is 0.8904. The line crosses the y (vertical) axis at 6.027, which is b. R^2, which is also known as the coefficient of determination, is 0.7928. From R^2, we can easily see that the correlation R is 0.8904 (square root of R^2). We know this is a highly positive correlation because we can visually verify it simply from the orientation of the slope. We can interpret m as the value of y when x is zero and we can interpret b as the amount that y increases when x increases by one. From all of this, one can determine the amount that one variable influences the other.
Sorry, I beat this to death; you can probably find simpler explanations in a high school statistics textbook.
Trendless Analysis
This is a rather simple but complementary (intentional spelling) method that helps to validate the other two processes. This method focuses on the lack of a trend, or the amount of trendless time that is in the data. The first two methods focused on trending, and this one is focused on nontrending, all using the same raw data. Determining markets that do not trend will serve two purposes. One is to not use conventional trend-following techniques on them, and the other is that it can be good for mean reversion analysis. Table 10.7 shows the column headers; the definitions follow.
Up. This is the Total Trend average from Trendiness One multiplied by the Up Total from Trendiness Two.
Down. This is the Total Trend average from Trendiness One multiplied by the Down Total from Trendiness Two.
Trendless. This is the complement of the sum of the Up and Down values (1 – (Up + Down)).
Rank. This is the numerical rank of the Trendless column with the largest value equal to a rank of 1.
Table 10.8 shows the results using the Trendless methodology.
Comparison of Trendiness One Rank and Trendless Rank
Although I think this was quite obvious, Figure 10.7 shows the analysis math is consistent and acceptable. These two series should essentially be inversely correlated, and they are with coefficient of determination equal to one.
The following tables take the data from the full 109 indices and subdivide it into sectors, international, domestic, and time frames to ensure there is robustness across a variety of data. There are many indices that appear in many of, if not most of, these tables, but keeping data of that sort for comparison with others that are not so widely diversified will enhance the research.
These tables show all three trend method results. This first table consists of all the index data. The remaining ones contain subsets of the All table, such as Domestic, International, Commodities, Sectors, Data > 2000, Data > 1990, and Data > 1980. The reason for the data subsets is to ensure there is a robust analysis in place across various lengths of data, which means multiple bull-and-bear cyclical markets are considered in addition to secular markets. The Data > 2000 means that the data starts sometime prior to 2000 and therefore totally contains the secular bear market that began in 2000.
All Trendiness Analysis
Table 10.9 contains data from all of the 109 indices in the analysis. The first column contains letters identifying the subcategory for each issue as follows:
I – International
S – Sector
C – Commodity
Blank – Domestic
Trend Table Selective Analysis
In this section, I will demonstrate more details on selected issues from Table 10.9 to show how the data can be utilized.
Using the Trendiness One Rank, you can see that the U.S. Dollar Index is number one. You can also see it is the worst for being Trendless (last column), which one would expect. However, if you look at the Trendiness One and Trendiness Two Up Ranks, you see that it did not rank well. This can only be interpreted that the U.S. Dollar Index is a good downtrending issue, but not a good uptrending one based on this relative analysis with 109 various indices. This is made clear from the long trendline drawn from the first data point to the last data point and is clearly in a downtrend.
Figure 10.8 shows the U.S. Dollar Index with a 5% filtered wave overlaid on it. The lower plot shows the filtered wave of 5% measuring the number of days during each up and down move. The two horizontal lines are at +21 and -21, which means that movements inside that band are not counted in the trendiness or trendless calculations. The only difference between what this chart shows and what the table data measures is the fact that the table is averaging a number of different filtered waves and trend lengths.
Let’s now look at the worst trendiness index and see what we can find out about it (Table 10.9). The Trendiness One rank and the Trendless Rank confirm that this is not a good trending index. Furthermore, the Up Trendiness in both One and Two also shows that it ranks low (109 and 81) in the Trendiness One, which is measuring the trendiness based on all the data, and that the rank in Trendiness Two is high (4). Remember that Trendiness Two only looks at the trending data, not all of the data. Therefore, you can say that this index when in a trending mode, tends to trend up well, but the problem is that it isn’t in a trending mode often (see Table 10.11).
Figure 10.9 shows the Turkey ISE National-100 index with the same format as the earlier analysis. Notice that it is generally in an uptrend based on the long-term trend line. From the bottom plot, you can see that there is very little movement of trends outside of the +21 and -21 day bands. Bottom line is that this index doesn’t trend well, and is quite volatile in its price movements; if you are trend follower; don’t waste your time with this one. A question that might arise is that it is also clear from the top plot that it is in an uptrend, so if you used a larger filtered wave and/or different trend length, it might yield different results. My response to that is simply: of course it will, you can fit the analysis to get any results you want, especially with all this wonderful hindsight. Bad approach to successful trend following.
Using the same data table, let’s look at an index that ranks high in the uptrend rankings (Table 10.9). From the table it ranks as middle of the road relatively based on Trendiness One and Trendless rank. However, the rank for Up Trendiness One and Trendiness Two Up rank is high (both are 5). This means that most of the trendiness is to the upside with only moderate downtrends (see Table 10.12).
Figure 10.10 shows the Norway Oslo Index clearly in an uptrend. The bottom plot shows that most of the spikes of trend length are above the +21 band level and very few are below the .21 band level. This confirms the data in the table.
In order to carry this analysis to fruition, let’s look at the index with the worst uptrend rank (Table 10.9). From the table, the Trendiness One and Two Up ranks are dead last (109). The Trendiness One overall rank is 104, which is almost last, and the trendless rank is 6, which confirms that data (see Table 10.13).
Figure 10.11 shows that the Hanoi SE Index is clearly in a downtrend; however, the bottom plot shows that very few trends are outside the bands. And the ones that move well outside the bands are the downtrends. As before, one can change the analysis and get desired results, but that is not how it should be done. One note, however, is that this index does not have a great deal of data compared to most of the others and this should be a consideration in the overall analysis.
Thanks for reading this far. I intend to publish one article in this series every week. Can’t wait? The book is for sale here.






